Вступление
Графики - это удобный способ хранения определенных типов данных. Концепция была перенесена из математики и адаптирована для нужд информатики.
Из-за того, что многие вещи можно представить в виде графиков, обход графов стал обычной задачей, особенно используемой в науке о данных и машинном обучении.
- Графики на Java
- Представление графиков в коде
- Поиск в глубину (DFS)
- Поиск в ширину (BFS)
- Алгоритм Дейкстры
Поиск в глубину
Поиск в глубину (DFS) ищет как можно дальше по ветке, а затем возвращается, чтобы найти как можно дальше в следующей ветке. Это означает, что в последующем графике он начинается с первого соседа и продолжается по строке, насколько это возможно:
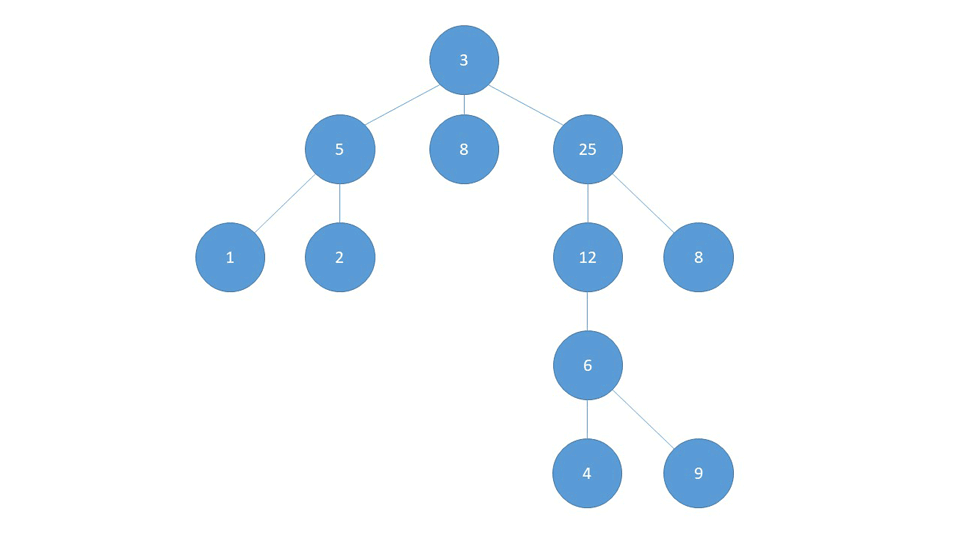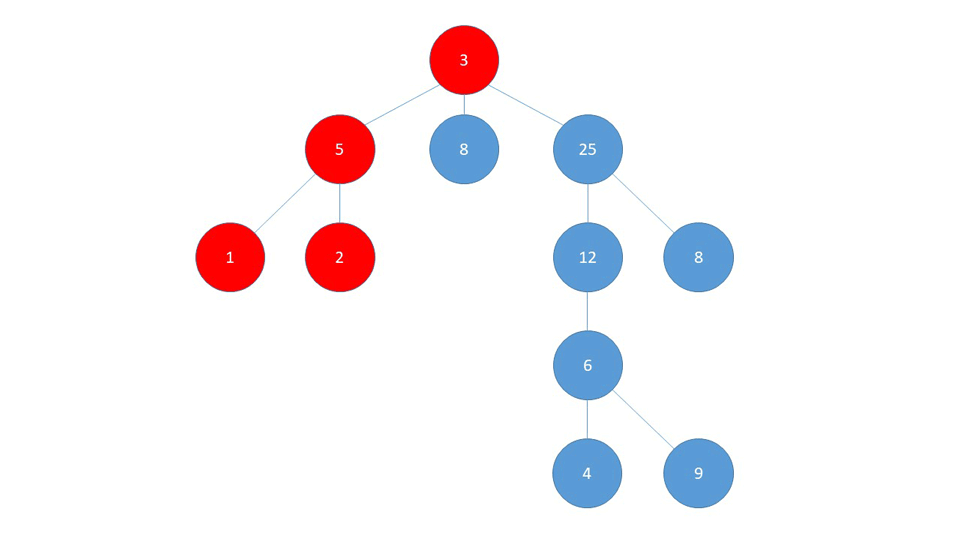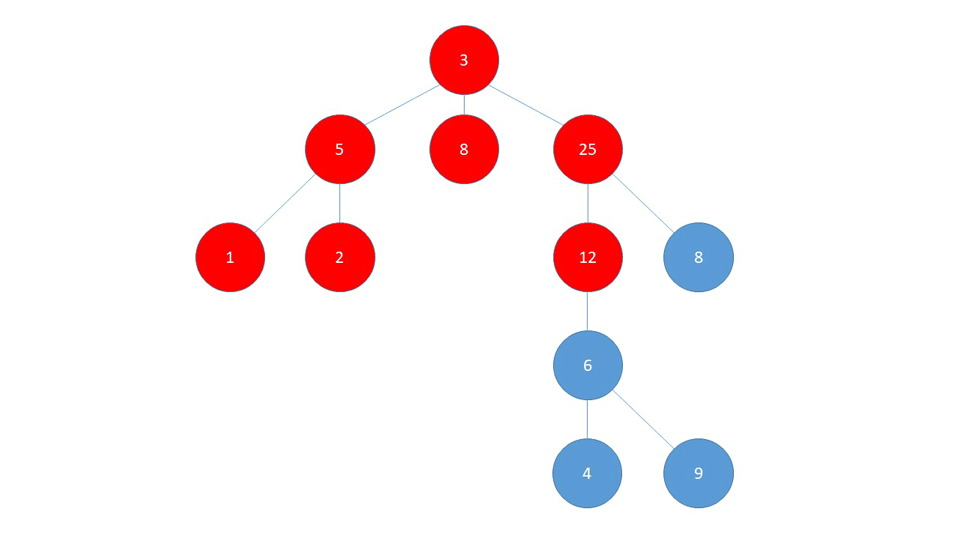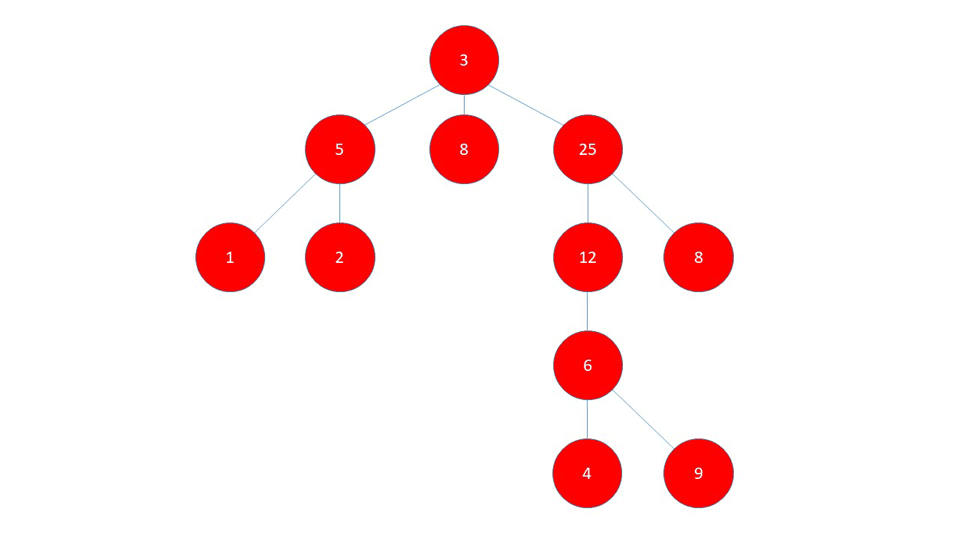
Достигнув последнего узла в этой ветви (1), он возвращается к первому узлу, где столкнулся с возможностью изменить курс (5), и посещает всю эту ветку, которой в нашем случае является узел (2).
Затем он снова возвращается к узлу (5), и, поскольку он уже посетил узлы (1) и (2), он возвращается к (3) и перенаправляет на следующую ветвь (8).
Выполнение
Поскольку мы знаем, как представлять графы в коде через списки смежности и матрицы, давайте сделаем граф и проходим его с помощью DFS. Графики, с которыми мы будем работать, достаточно просты, поэтому не имеет значения, какую реализацию мы выберем.
Хотя для реальных проектов в большинстве случаев списки смежности будут лучшим выбором, поэтому мы собираемся представить граф как список смежности.
Мы хотим посетить все наши узлы один раз, как видно на анимации выше,
они становятся красными после посещения, поэтому мы больше их не
посещаем. Чтобы сделать это в коде, мы введем флаг visited
public class Node {
int n;
String name;
boolean visited; // New attribute
Node(int n, String name) {
this.n = n;
this.name = name;
visited = false;
}
// Two new methods we'll need in our traversal algorithms
void visit() {
visited = true;
}
void unvisit() {
visited = false;
}
}
Теперь давайте определим Graph :
public class Graph {
// Each node maps to a list of all his neighbors
private HashMap<Node, LinkedList<Node>> adjacencyMap;
private boolean directed;
public Graph(boolean directed) {
this.directed = directed;
adjacencyMap = new HashMap<>();
}
// ...
}
Теперь добавим метод addEdge() . Мы будем использовать два метода:
вспомогательный и фактический.
Во вспомогательном методе мы также проверим возможные повторяющиеся
края. Прежде чем добавить край между A и B , мы сначала удалим
его, а только потом добавим. Если кромка уже существует, это не
позволяет нам добавить повторяющуюся кромку. Если там еще не было ребра,
то у нас все еще есть только одно ребро между двумя узлами.
Если край не существует, удаление несуществующего края приведет к
исключению NullPointerException поэтому мы вводим временную копию
списка:
public void addEdgeHelper(Node a, Node b) {
LinkedList<Node> tmp = adjacencyMap.get(a);
if (tmp != null) {
tmp.remove(b);
}
else tmp = new LinkedList<>();
tmp.add(b);
adjacencyMap.put(a, tmp);
}
public void addEdge(Node source, Node destination) {
// We make sure that every used node shows up in our .keySet()
if (!adjacencyMap.keySet().contains(source))
adjacencyMap.put(source, null);
if (!adjacencyMap.keySet().contains(destination))
adjacencyMap.put(destination, null);
addEdgeHelper(source, destination);
// If a graph is undirected, we want to add an edge from destination to source as well
if (!directed) {
addEdgeHelper(destination, source);
}
}
Наконец, у нас будут довольно простые вспомогательные методы
printEdges() , hasEdge() и resetNodesVisited()
public void printEdges() {
for (Node node : adjacencyMap.keySet()) {
System.out.print("The " + node.name + " has an edge towards: ");
for (Node neighbor : adjacencyMap.get(node)) {
System.out.print(neighbor.name + " ");
}
System.out.println();
}
}
public boolean hasEdge(Node source, Node destination) {
return adjacencyMap.containsKey(source) && adjacencyMap.get(source).contains(destination);
}
public void resetNodesVisited(){
for(Node node : adjacencyMap.keySet()){
node.unvisit();
}
}
Мы также добавим в наш Graph depthFirstSearch(Node node) который
выполняет следующие действия:
- Если
node.visited == true, просто верните - Если он еще не был посещен, сделайте следующее:
- Найдите первого
newNodenodeи вызовитеdepthFirstSearch(newNode) - Повторите процесс для всех непосещенных соседей.
- Найдите первого
Проиллюстрируем это на примере:
Node A is connected with node D
Node B is connected with nodes D, C
Node C is connected with nodes A, B
Node D is connected with nodes B
- Вначале все узлы не
node.visited == false) - Вызовите
.depthFirstSeach()с произвольным узлом в качестве начального узла, скажем,depthFirstSearch(B) - отметить B как посещенный
- Есть ли у B незнакомые соседи? Да -> первый непосещенный узел - это
D, поэтому вызовите
depthFirstSearch(D) - отметить D как посещенный
- Есть ли у D непосещаемые соседи? Нет -> (B уже посещали) вернуться
- Есть ли у B незнакомые соседи? Да -> первый непосещенный узел - это
C, поэтому вызовите
depthFirstSearch(C) - отметить C как посещенный
- Есть ли у C невидимые соседи? Да -> первый непосещенный узел - A,
поэтому вызовите
depthFirstSearch(A) - отметить А как посещенный
- Есть ли у A непосещаемые соседи? Нет -> возврат
- Есть ли у C невидимые соседи? Нет -> возврат
- Есть ли у B незнакомые соседи? Нет -> возврат
Вызов DFS на нашем графе даст нам обход B, D, C, A (порядок посещения). Когда алгоритм написан так, его легко перевести в код:
public void depthFirstSearch(Node node) {
node.visit();
System.out.print(node.name + " ");
LinkedList<Node> allNeighbors = adjacencyMap.get(node);
if (allNeighbors == null)
return;
for (Node neighbor : allNeighbors) {
if (!neighbor.isVisited())
depthFirstSearch(neighbor);
}
}
Опять же, вот как это выглядит при переводе в анимацию:
DFS иногда называют «агрессивным» обходом графа, потому что он проходит настолько далеко, насколько это возможно, через одну «ветвь». Как мы можем видеть в GIF выше, когда встречает DFS узел 25, она заставляет 25 - 12 - 6 - 4 ветки , пока она не может идти дальше. Только после этого алгоритм возвращается к проверке других непосещенных соседей предыдущих узлов, начиная с тех, которые посещались недавно.
Примечание: у нас может быть несвязанный график. Несвязанный граф - это граф, у которого нет пути между любыми двумя узлами.
{.ezlazyload}
В этом примере будут посещены узлы 0, 1 и 2, и выходные данные будут отображать эти узлы и полностью игнорировать узлы 3 и 4.
То же самое произошло бы, если бы мы вызвали depthFirstSearch(4) ,
только на этот раз 4 и 3 были бы посещены, а 0, 1 и 2 - нет. Решение
этой проблемы - продолжать вызывать DFS до тех пор, пока есть какие-либо
непосещенные узлы.
Это можно сделать несколькими способами, но мы можем внести еще одну
небольшую модификацию в наш Graph чтобы справиться с этой проблемой.
Мы добавим новый depthFirstSearchModified(Node node) :
public void depthFirstSearchModified(Node node) {
depthFirstSearch(node);
for (Node n : adjacencyMap.keySet()) {
if (!n.isVisited()) {
depthFirstSearch(n);
}
}
}
public void depthFirstSearch(Node node) {
node.visit();
System.out.print(node.name + " ");
LinkedList<Node> allNeighbors = adjacencyMap.get(node);
if (allNeighbors == null)
return;
for (Node neighbor : allNeighbors) {
if (!neighbor.isVisited())
depthFirstSearch(neighbor);
}
}
public class GraphShow {
public static void main(String[] args) {
Graph graph = new Graph(false);
Node a = new Node(0, "0");
Node b = new Node(1, "1");
Node c = new Node(2, "2");
Node d = new Node(3, "3");
Node e = new Node(4, "4");
graph.addEdge(a,b);
graph.addEdge(a,c);
graph.addEdge(c,b);
graph.addEdge(e,d);
System.out.println("If we were to use our previous DFS method, we would get an incomplete traversal");
graph.depthFirstSearch(b);
graph.resetNodesVisited(); // All nodes are marked as visited because of
// the previous DFS algorithm so we need to
// mark them all as not visited
System.out.println();
System.out.println("Using the modified method visits all nodes of the graph, even if it's unconnected");
graph.depthFirstSearchModified(b);
}
}
Что дает нам результат:
If we were to use our previous DFS method, we would get an incomplete traversal
1 0 2
Using the modified method visits all nodes of the graph, even if it's unconnected
1 0 2 4 3
Давайте запустим наш алгоритм еще на одном примере:
{.ezlazyload}
public class GraphShow {
public static void main(String[] args) {
Graph graph = new Graph(true);
Node zero = new Node(0, "0");
Node one = new Node(1, "1");
Node two = new Node(2, "2");
Node three = new Node(3, "3");
Node four = new Node(4, "4");
Node five = new Node(5, "5");
Node six = new Node(6, "6");
Node seven = new Node(7, "7");
Node eight = new Node(8, "8");
graph.addEdge(one,zero);
graph.addEdge(three,one);
graph.addEdge(two,seven);
graph.addEdge(two,four);
graph.addEdge(five,two);
graph.addEdge(five,zero);
graph.addEdge(six,five);
graph.addEdge(six,three);
graph.addEdge(six,eight);
graph.addEdge(seven,five);
graph.addEdge(seven,six);
graph.addEdge(seven,eight);
graph.depthFirstSearch(seven);
}
}
Это дает нам результат:
7 5 2 4 0 6 3 1 8
Заказ соседей
Еще одна "забавная" вещь, которую мы, возможно, захотим добавить, -
это некоторый порядок, в котором соседи перечислены для каждого узла. Мы
можем добиться этого, используя структуру данных кучи ( PriorityQueue
в Java) вместо LinkedList для соседей и реализуя compareTo() в нашем
Node чтобы Java знала, как сортировать наши объекты:
public class Node implements Comparable<Node> {
// Same code as before...
public int compareTo(Node node) {
return this.n - node.n;
}
}
class Graph {
// Replace all occurrences of LinkedList with PriorityQueue
}
public class GraphShow {
public static void main(String[] args) {
GraphAdjacencyList graph = new GraphAdjacencyList(true);
Node a = new Node(0, "0");
Node b = new Node(1, "1");
Node c = new Node(2, "2");
Node d = new Node(3, "3");
Node e = new Node(4, "4");
graph.addEdge(a,e);
graph.addEdge(a,d);
graph.addEdge(a,b);
graph.addEdge(a,c);
System.out.println("When using a PriorityQueue, it doesn't matter in which order we add neighbors, they will always be sorted");
graph.printEdges();
System.out.println();
graph.depthFirstSearchModified(a);
graph.resetNodesVisited();
}
}
When using a PriorityQueue, it doesn't matter in which order we add neighbors, they will always be sorted
The 0 has an edge towards: 1 2 3 4
0 1 2 3 4
Если бы мы не использовали PriorityQueue , вывод DFS был бы
0,4,3,1,2 .
Заключение
Графики - это удобный способ хранения определенных типов данных. Концепция была перенесена из математики и адаптирована для нужд информатики.
Из-за того, что многие вещи можно представить в виде графиков, обход графов стал обычной задачей, особенно используемой в науке о данных и машинном обучении.
Поиск в глубину (DFS) - это один из немногих алгоритмов обхода графа, который выполняет поиск как можно дальше вдоль ветви, а затем возвращается назад, чтобы искать как можно дальше в следующей ветви.